VibeVoice 文本转语音
一个创新的框架,用于从文本生成富有表现力的长对话多说话人音频。采用超低帧率分词器和下一词扩散技术,可生成长达90分钟、最多4个不同说话人的高质量语音合成。
主要特性
- •长对话音频生成(最长90分钟)
- •多说话人支持(最多4个不同说话人)
- •超低帧率分词器(7.5 Hz)
- •下一词扩散框架
🎁 体验对话文本转语音技术的未来
什么是 VibeVoice
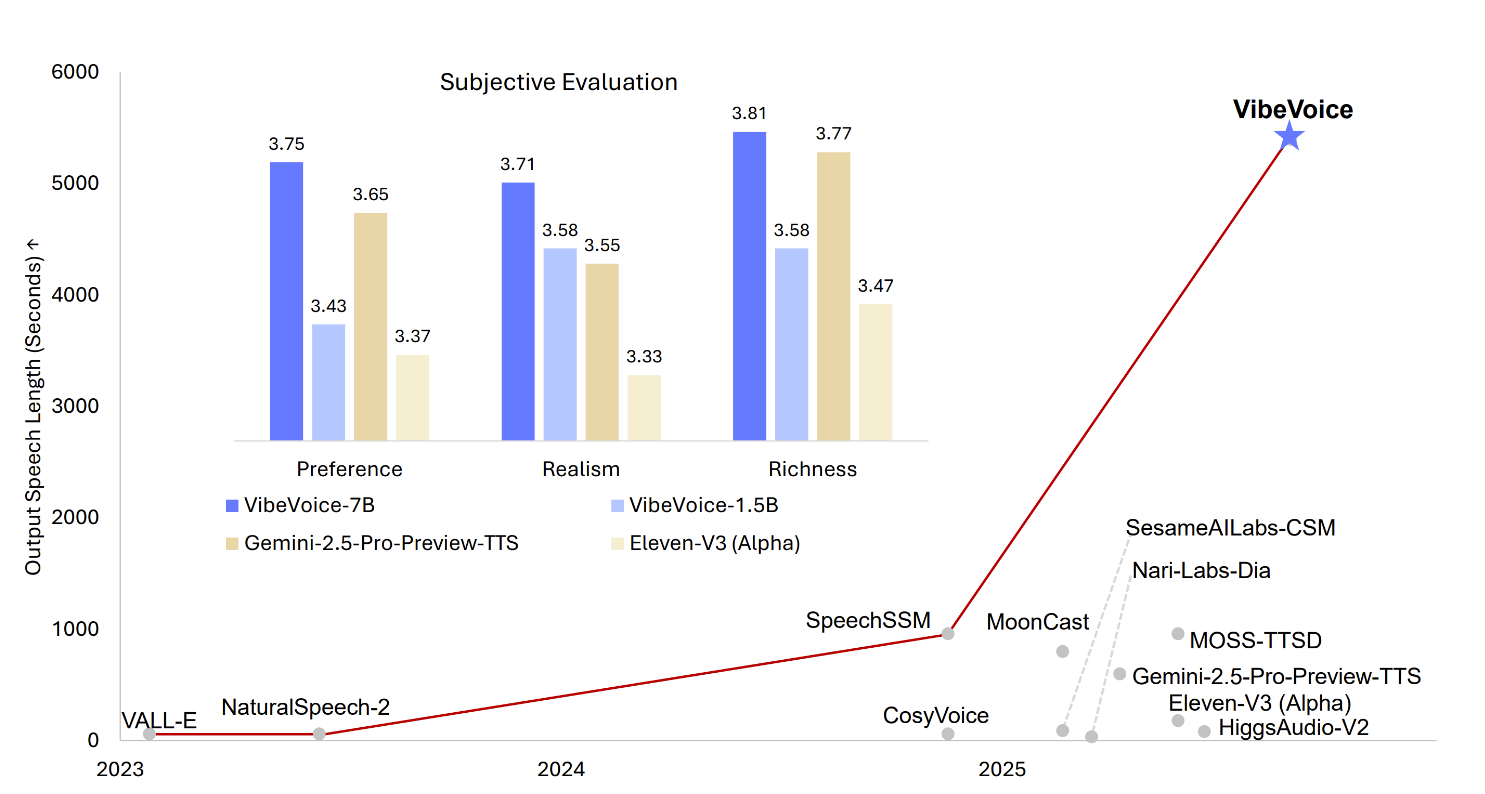
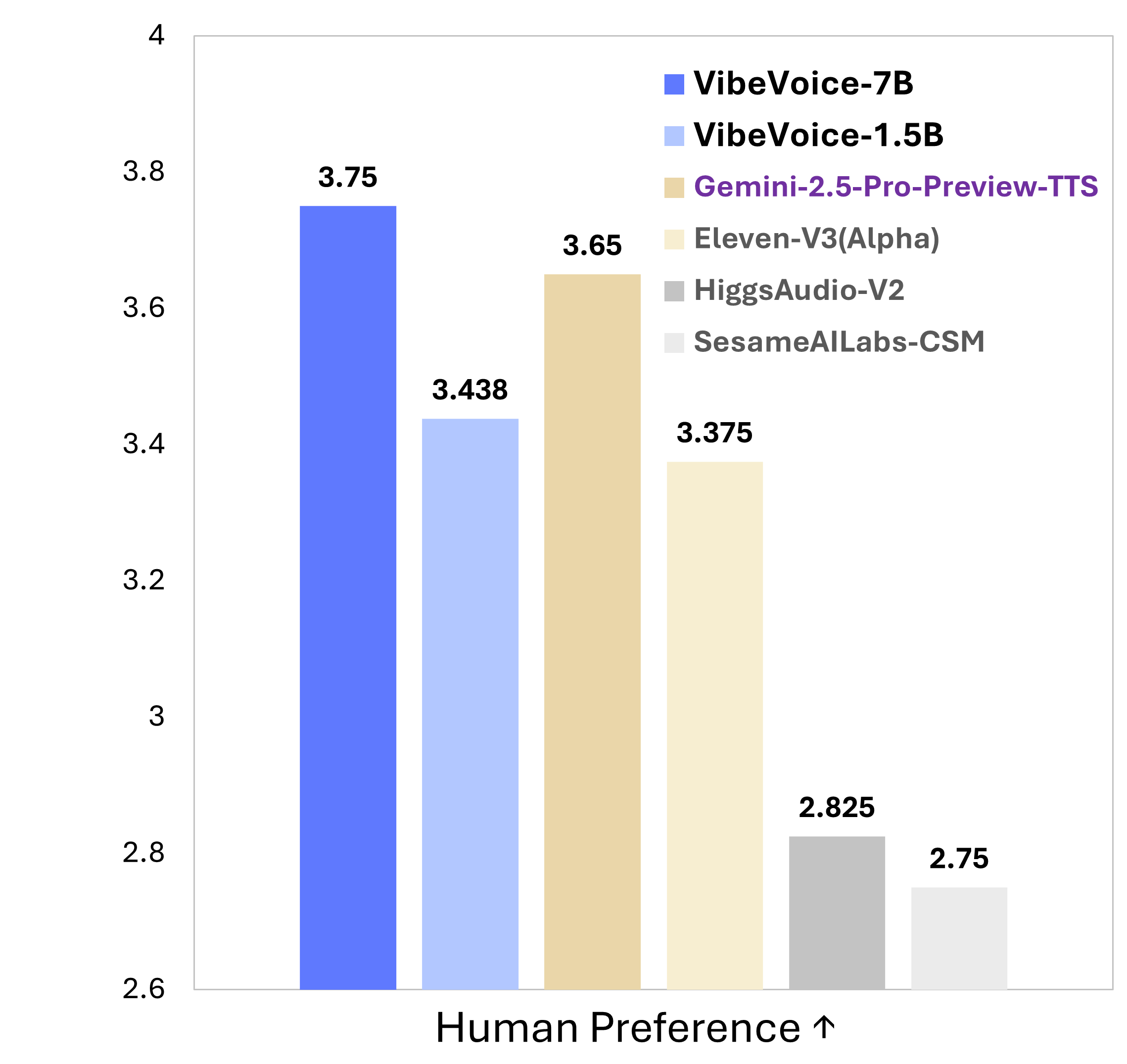
VibeVoice 是一个创新的框架,专门用于从文本生成富有表现力的长对话多说话人音频。它解决了传统TTS系统在可扩展性、说话人一致性和自然对话转换方面的重大挑战。
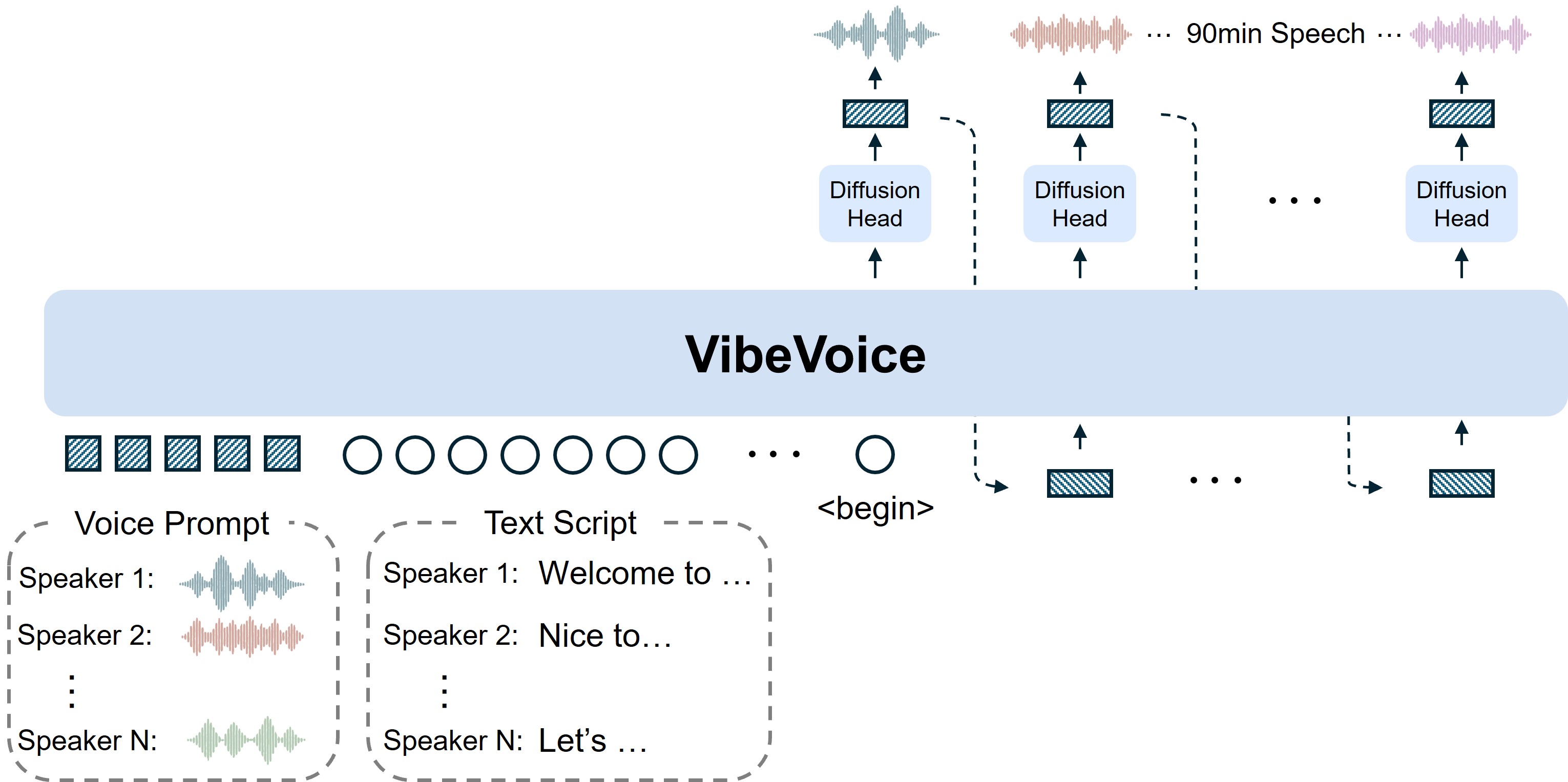
- 连续语音分词器使用声学和语义分词器,以7.5 Hz的超低帧率运行,在提升计算效率的同时有效保持音频保真度。
- 下一词扩散框架利用大语言模型理解文本上下文和对话流程,通过扩散头生成高保真度的声学细节。
- 长对话多说话人支持可合成长达90分钟的语音,支持最多4个不同说话人,超越了以往模型通常1-2个说话人的限制。
为什么选择 VibeVoice
体验对话文本转语音技术的突破性创新,具备前所未有的可扩展性和自然对话生成能力。
VibeVoice 的独特之处
VibeVoice 是一个突破性的框架,以其创新的架构和前所未有的能力革新了对话文本转语音技术。
连续语音分词器
声学和语义分词器以7.5 Hz的超低帧率运行,实现高效的长序列处理
下一词扩散框架
结合LLM理解和扩散头,生成高保真度的声学细节
长对话多说话人支持
生成长达90分钟的音频,支持最多4个不同说话人的自然对话
表达性对话音频
专门为播客、访谈和多说话人对话设计,具备自然的对话转换
可扩展架构
解决传统TTS在可扩展性、说话人一致性和自然对话流程方面的挑战
研究框架
开源研究框架,旨在推进语音合成社区的协作发展
用户如何评价 VibeVoice
听听社区对 VibeVoice 的看法。
Been playing with Microsoft’s VibeVoice, MIT-licensed TTS that does ~90-minute narrations, multi-speaker, cross-lingual.
— Sai (@SAIT112024) August 30, 2025
Streaming and a larger checkpoint are coming. Let’s just say it drops neatly into a local-first stack I care about. pic.twitter.com/TCxDcmAgDj
VibeVoice might be the best FREE text to speech & voice cloner right now.
— ⚡AI Search⚡ (@aisearchio) September 3, 2025
- Over 90min generations
- Up to 4 speakers
- Auto expressions
- Can run on consumer GPUs
See my full tutorial: https://t.co/UnbBzSMZA9 pic.twitter.com/yFDaqEbd5U
VibeVoice 复活啦!
— karminski-牙医 (@karminski3) September 15, 2025
我是没想到 VibeVoice 都快变成 电视剧了,最近社区爱好者们自发的从VibeVoice 历史提交中成功找回了未经河蟹的版本,然后放到了 HuggingFace。由于微软当初是 MIT协议发布的,所以微软也没办法下架这个恢复出来的模型了。
总之,如果你想用 VibeVoice… pic.twitter.com/VxMAklY8kL
微软新开源了这个 VibeVoice TTS模型很强
— 歸藏(guizang.ai) (@op7418) August 26, 2025
- 支持最多生成 90 分钟时长
- 最多4 个人的对谈语音,以往模型只能生成两个
- 支持中文,而且中文效果不错
- 支持生成带背景音乐的播客音频 pic.twitter.com/gnHDl3Apmj
💬 Microsoft > VibeVoice 모델 공개
— lucas (@lucas_flatwhite) September 2, 2025
마이크로소프트에서 공개한 VibeVoice는 텍스트를 입력받아 자연스러운 대화 형식의 오디오를 생성하는 오픈소스 TTS(Text-to-Speech) 모델이에요.
VibeVoice: A Frontier Open-Source Text-to-Speech Modelhttps://t.co/iveNf3unot
Hugging Face… pic.twitter.com/BSlyQItasF
【速報🔥】超高性能TTS「VibeVoice」がコミュニティ主導で劇的復活🎉 長時間&複数人会話音声生成がクリエイターの強力な武器に!
— ハカセ アイ(Ai-Hakase)🐾最新トレンドAIのためのX 🐾 (@ai_hakase_) September 15, 2025
Microsoftが中止した超高性能TTS「VibeVoice」が、コミュニティの情熱で「VibeVoice-Community」として劇的復活しましたよ!🎉… pic.twitter.com/n2k5ROEzQv
关于 VibeVoice 的常见问题
还有其他问题?通过电子邮件联系我们。
VibeVoice 的设计用途是什么?
VibeVoice 专门用于从文本生成富有表现力的长对话多说话人音频,如播客、访谈和扩展对话。
VibeVoice 能生成多长的音频?
VibeVoice 可以合成长达90分钟的语音,远超传统TTS系统通常处理的短序列。
VibeVoice 能处理多少个说话人?
VibeVoice 在单个对话中支持最多4个不同说话人,在整个音频中保持自然的对话转换和说话人一致性。
VibeVoice 支持哪些语言?
VibeVoice 目前支持英语和中文。其他语言的文本可能导致意外的音频输出。
VibeVoice 适合商业使用吗?
VibeVoice 仅用于研究和开发目的。我们不建议在没有进一步测试和开发的情况下将其用于商业或实际应用。
准备好体验 VibeVoice 了吗?
体验对话文本转语音技术的强大功能。