VibeVoice Text-to-Speech
A novel framework for generating expressive, long-form, multi-speaker conversational audio from text. Features ultra-low frame rate tokenizers and next-token diffusion for high-quality speech synthesis up to 90 minutes with 4 distinct speakers.
Key Features
- •Long-form conversational audio (up to 90 minutes)
- •Multi-speaker support (up to 4 distinct speakers)
- •Ultra-low frame rate tokenizers (7.5 Hz)
- •Next-token diffusion framework
🎁 Experience the future of conversational text-to-speech technology
What is VibeVoice
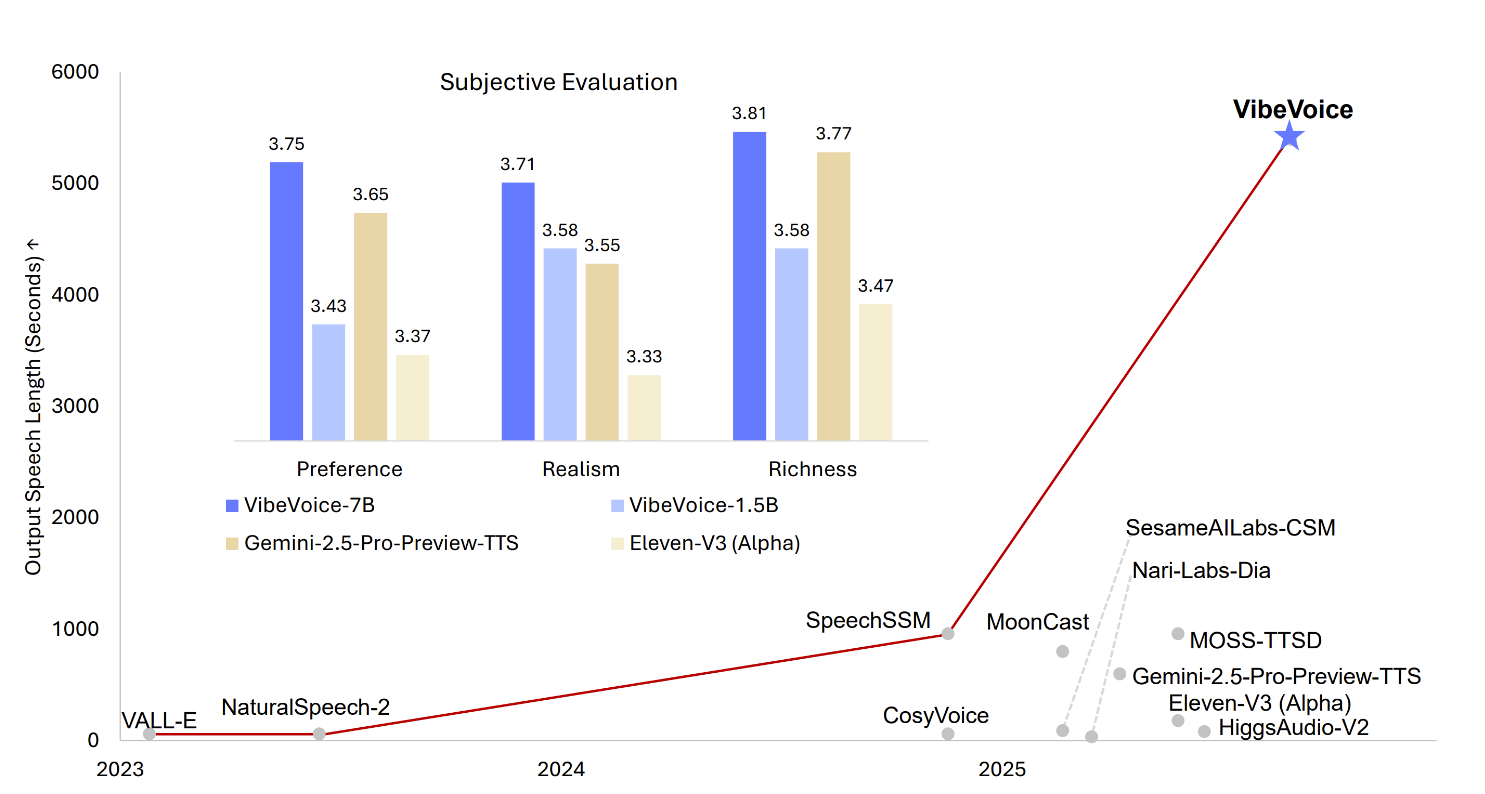
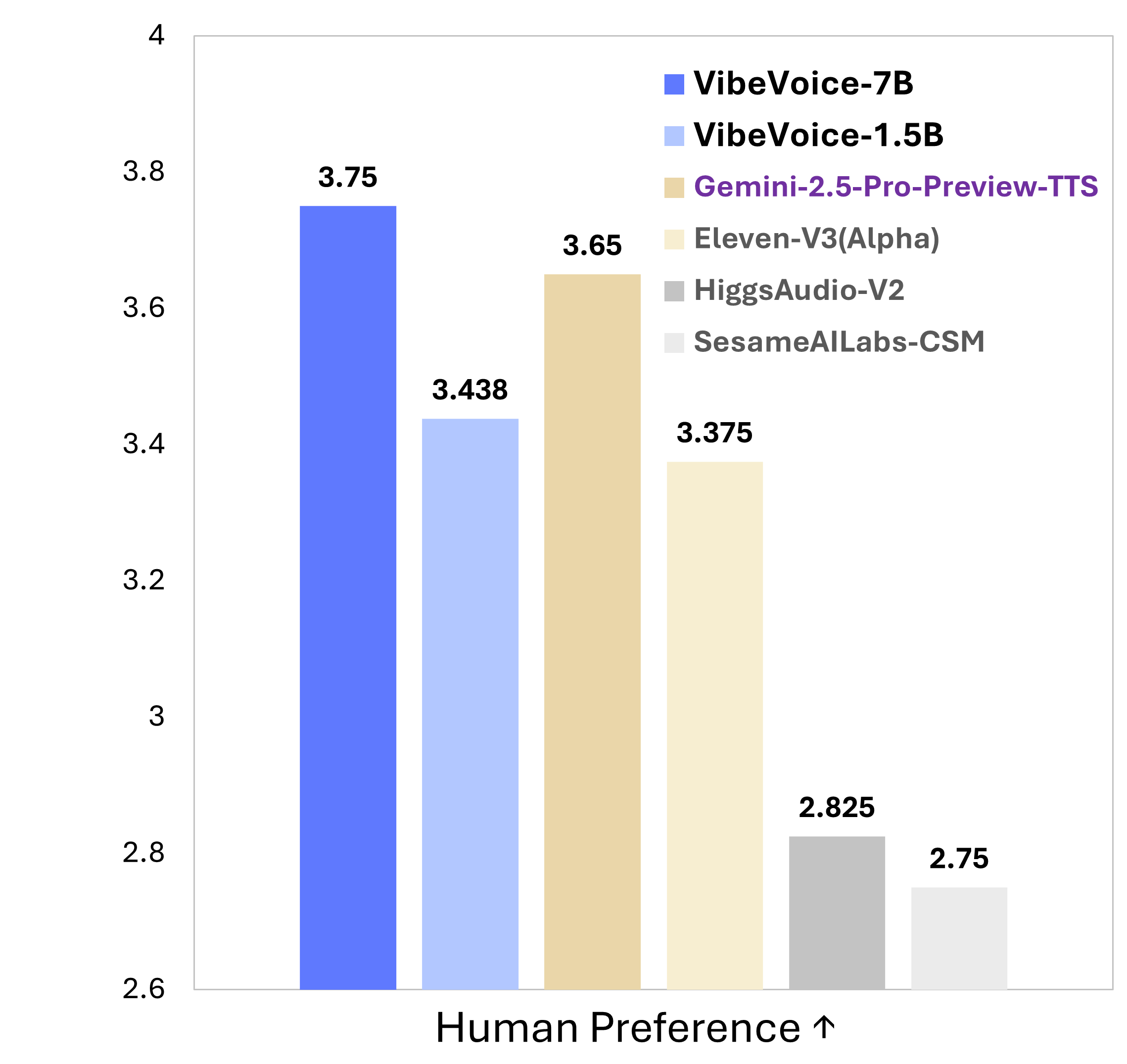
VibeVoice is a novel framework designed for generating expressive, long-form, multi-speaker conversational audio from text. It addresses significant challenges in traditional TTS systems, particularly in scalability, speaker consistency, and natural turn-taking.
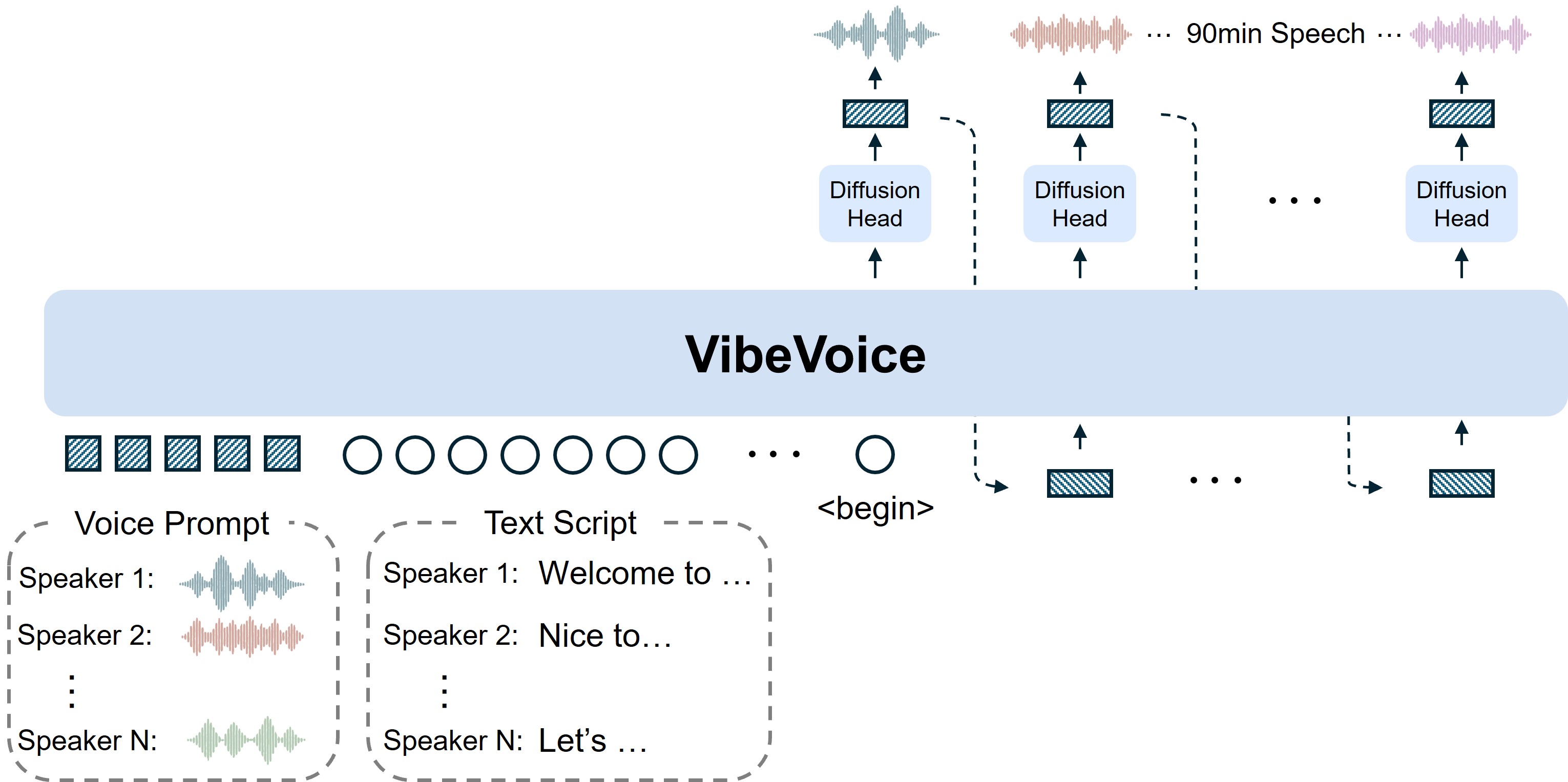
- Continuous Speech TokenizersUses Acoustic and Semantic tokenizers operating at ultra-low frame rate of 7.5 Hz, efficiently preserving audio fidelity while boosting computational efficiency.
- Next-Token Diffusion FrameworkLeverages Large Language Model to understand textual context and dialogue flow, with diffusion head to generate high-fidelity acoustic details.
- Long-Form Multi-Speaker SupportSynthesizes speech up to 90 minutes long with up to 4 distinct speakers, surpassing typical 1-2 speaker limits of prior models.
Why Choose VibeVoice
Experience breakthrough technology in conversational text-to-speech with unprecedented scalability and natural dialogue generation.
What makes VibeVoice special
VibeVoice is a breakthrough framework that revolutionizes conversational text-to-speech with its innovative architecture and unprecedented capabilities.
Continuous Speech Tokenizers
Acoustic and Semantic tokenizers operating at ultra-low 7.5 Hz frame rate for efficient long-sequence processing
Next-Token Diffusion Framework
Combines LLM understanding with diffusion head for high-fidelity acoustic detail generation
Long-Form Multi-Speaker Support
Generate up to 90 minutes of audio with up to 4 distinct speakers in natural conversations
Expressive Conversational Audio
Designed specifically for podcasts, interviews, and multi-speaker dialogues with natural turn-taking
Scalable Architecture
Addresses traditional TTS challenges in scalability, speaker consistency, and natural dialogue flow
Research Framework
Open-source research framework intended to advance collaboration in the speech synthesis community
What People Are Saying
See what the community thinks about VibeVoice.
Been playing with Microsoft’s VibeVoice, MIT-licensed TTS that does ~90-minute narrations, multi-speaker, cross-lingual.
— Sai (@SAIT112024) August 30, 2025
Streaming and a larger checkpoint are coming. Let’s just say it drops neatly into a local-first stack I care about. pic.twitter.com/TCxDcmAgDj
VibeVoice might be the best FREE text to speech & voice cloner right now.
— ⚡AI Search⚡ (@aisearchio) September 3, 2025
- Over 90min generations
- Up to 4 speakers
- Auto expressions
- Can run on consumer GPUs
See my full tutorial: https://t.co/UnbBzSMZA9 pic.twitter.com/yFDaqEbd5U
VibeVoice 复活啦!
— karminski-牙医 (@karminski3) September 15, 2025
我是没想到 VibeVoice 都快变成 电视剧了,最近社区爱好者们自发的从VibeVoice 历史提交中成功找回了未经河蟹的版本,然后放到了 HuggingFace。由于微软当初是 MIT协议发布的,所以微软也没办法下架这个恢复出来的模型了。
总之,如果你想用 VibeVoice… pic.twitter.com/VxMAklY8kL
微软新开源了这个 VibeVoice TTS模型很强
— 歸藏(guizang.ai) (@op7418) August 26, 2025
- 支持最多生成 90 分钟时长
- 最多4 个人的对谈语音,以往模型只能生成两个
- 支持中文,而且中文效果不错
- 支持生成带背景音乐的播客音频 pic.twitter.com/gnHDl3Apmj
💬 Microsoft > VibeVoice 모델 공개
— lucas (@lucas_flatwhite) September 2, 2025
마이크로소프트에서 공개한 VibeVoice는 텍스트를 입력받아 자연스러운 대화 형식의 오디오를 생성하는 오픈소스 TTS(Text-to-Speech) 모델이에요.
VibeVoice: A Frontier Open-Source Text-to-Speech Modelhttps://t.co/iveNf3unot
Hugging Face… pic.twitter.com/BSlyQItasF
【速報🔥】超高性能TTS「VibeVoice」がコミュニティ主導で劇的復活🎉 長時間&複数人会話音声生成がクリエイターの強力な武器に!
— ハカセ アイ(Ai-Hakase)🐾最新トレンドAIのためのX 🐾 (@ai_hakase_) September 15, 2025
Microsoftが中止した超高性能TTS「VibeVoice」が、コミュニティの情熱で「VibeVoice-Community」として劇的復活しましたよ!🎉… pic.twitter.com/n2k5ROEzQv
Frequently Asked Questions About VibeVoice
Have another question? Contact us by email.
What is VibeVoice designed for?
VibeVoice is designed for generating expressive, long-form, multi-speaker conversational audio such as podcasts, interviews, and extended dialogues from text input.
How long can VibeVoice generate audio?
VibeVoice can synthesize speech up to 90 minutes long, significantly longer than traditional TTS systems which typically handle much shorter sequences.
How many speakers can VibeVoice handle?
VibeVoice supports up to 4 distinct speakers in a single conversation, with natural turn-taking and speaker consistency throughout the entire audio.
What languages does VibeVoice support?
VibeVoice currently supports English and Chinese. Transcripts in other languages may result in unexpected audio outputs.
Is VibeVoice suitable for commercial use?
VibeVoice is intended for research and development purposes only. We do not recommend using it in commercial or real-world applications without further testing and development.
Ready to try VibeVoice?
Experience the power of conversational text-to-speech technology.