VibeVoice テキスト読み上げ
テキストから表現力豊かな長い多話者会話音声を生成する革新的なフレームワーク。超低周波数トークナイザーと次トークン拡散を使用して、最大4人の異なる話者で90分まで高品質な音声合成を実現。
主要機能
- •長い会話音声(最大90分)
- •多話者サポート(最大4人の異なる話者)
- •超低周波数トークナイザー(7.5 Hz)
- •次トークン拡散フレームワーク
🎁 会話型テキスト読み上げ技術の未来を体験
VibeVoiceとは
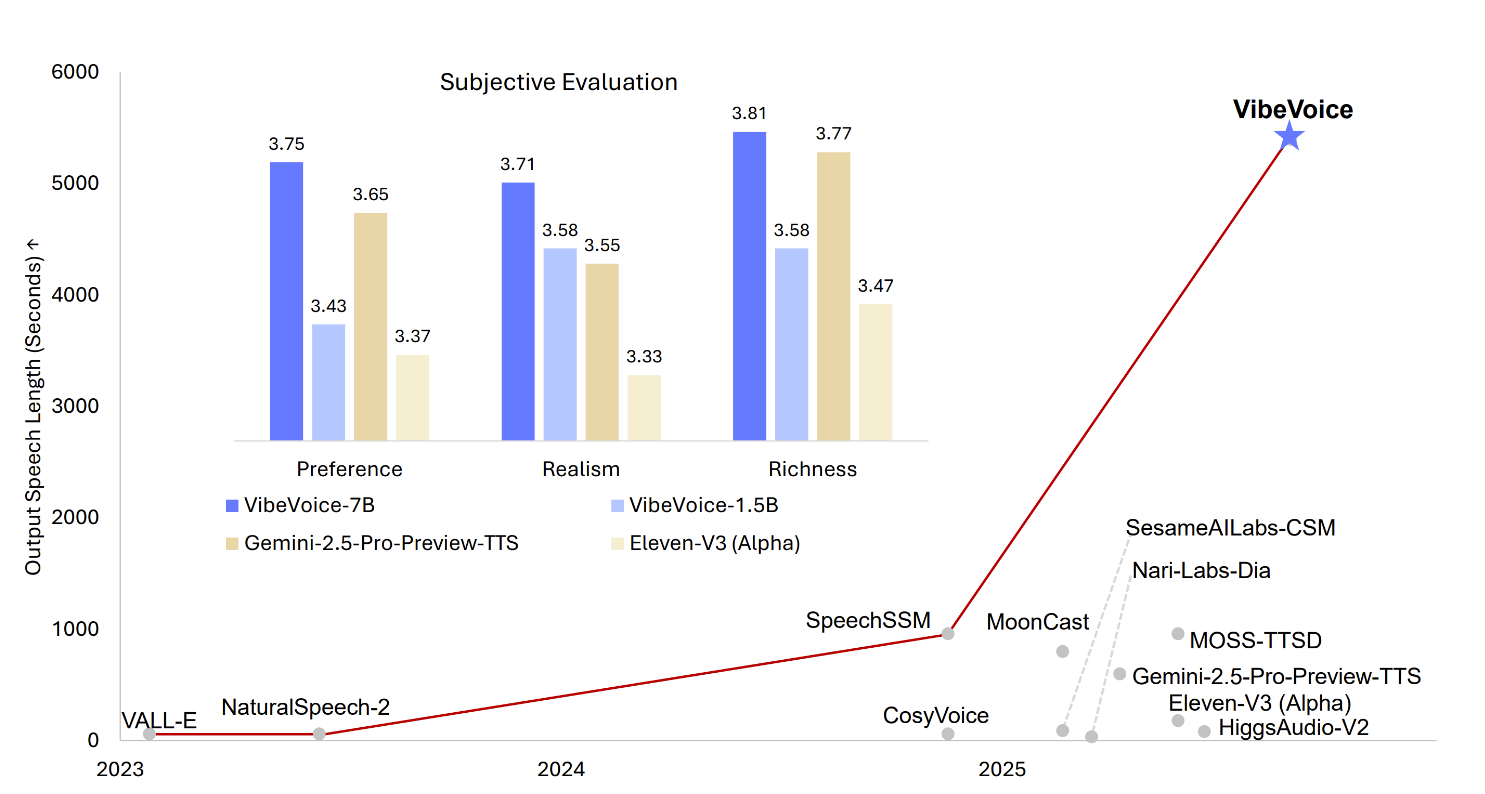
VibeVoiceは、テキストから表現力豊かな長い多話者会話音声を生成するために設計された革新的なフレームワークです。特にスケーラビリティ、話者一貫性、自然な話者交代の面で、従来のTTSシステムの重要な課題を解決します。
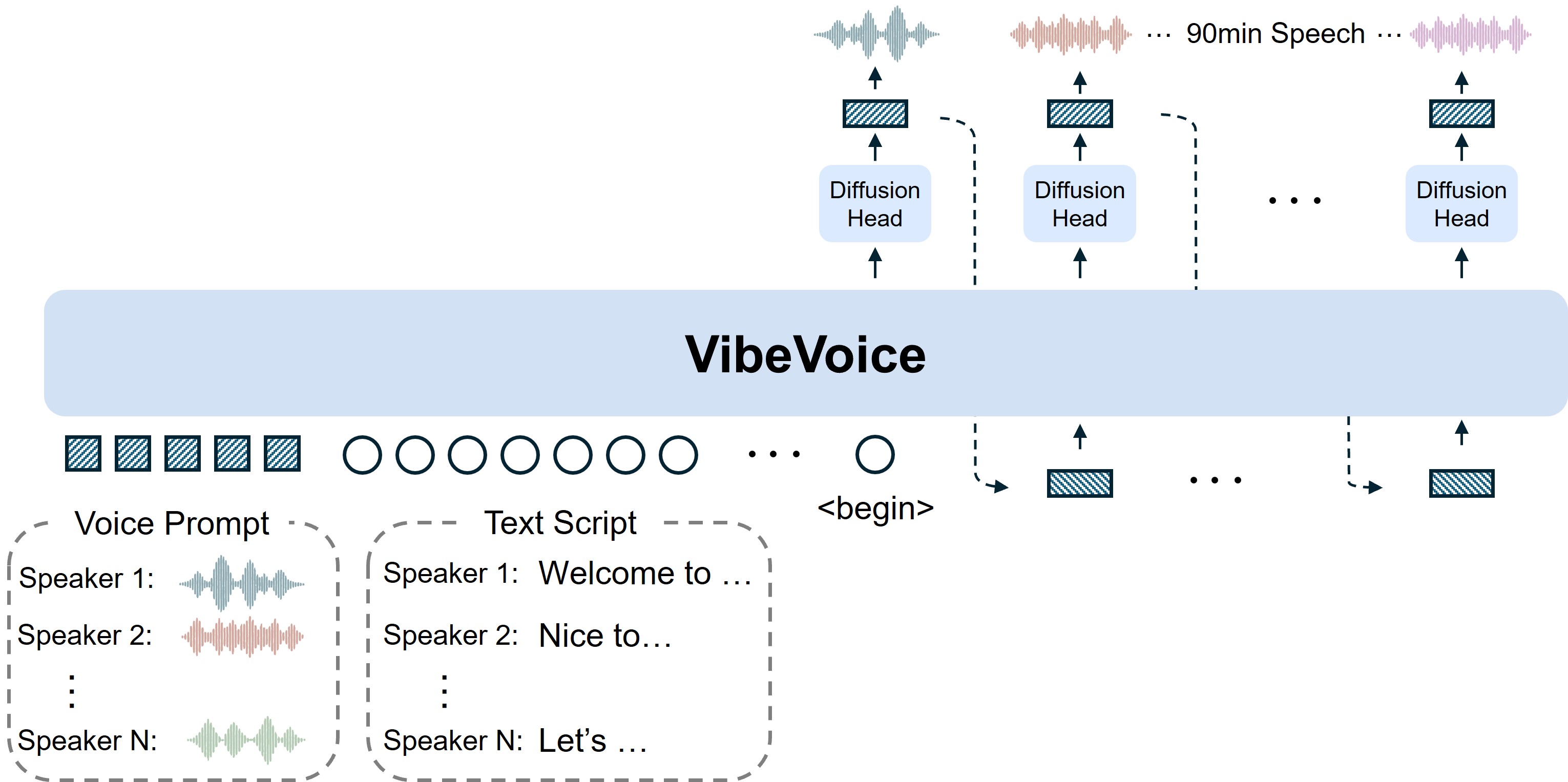
- 連続音声トークナイザー7.5 Hzの超低周波数で動作する音響および意味トークナイザーを使用し、計算効率を大幅に向上させながら音声忠実度を効率的に保持。
- 次トークン拡散フレームワーク大規模言語モデルを活用してテキストコンテキストと会話フローを理解し、拡散ヘッドで高品質な音響詳細を生成。
- 長い多話者サポート最大4人の異なる話者で最大90分まで音声を合成し、従来のモデルの典型的な1-2話者制限を上回る。
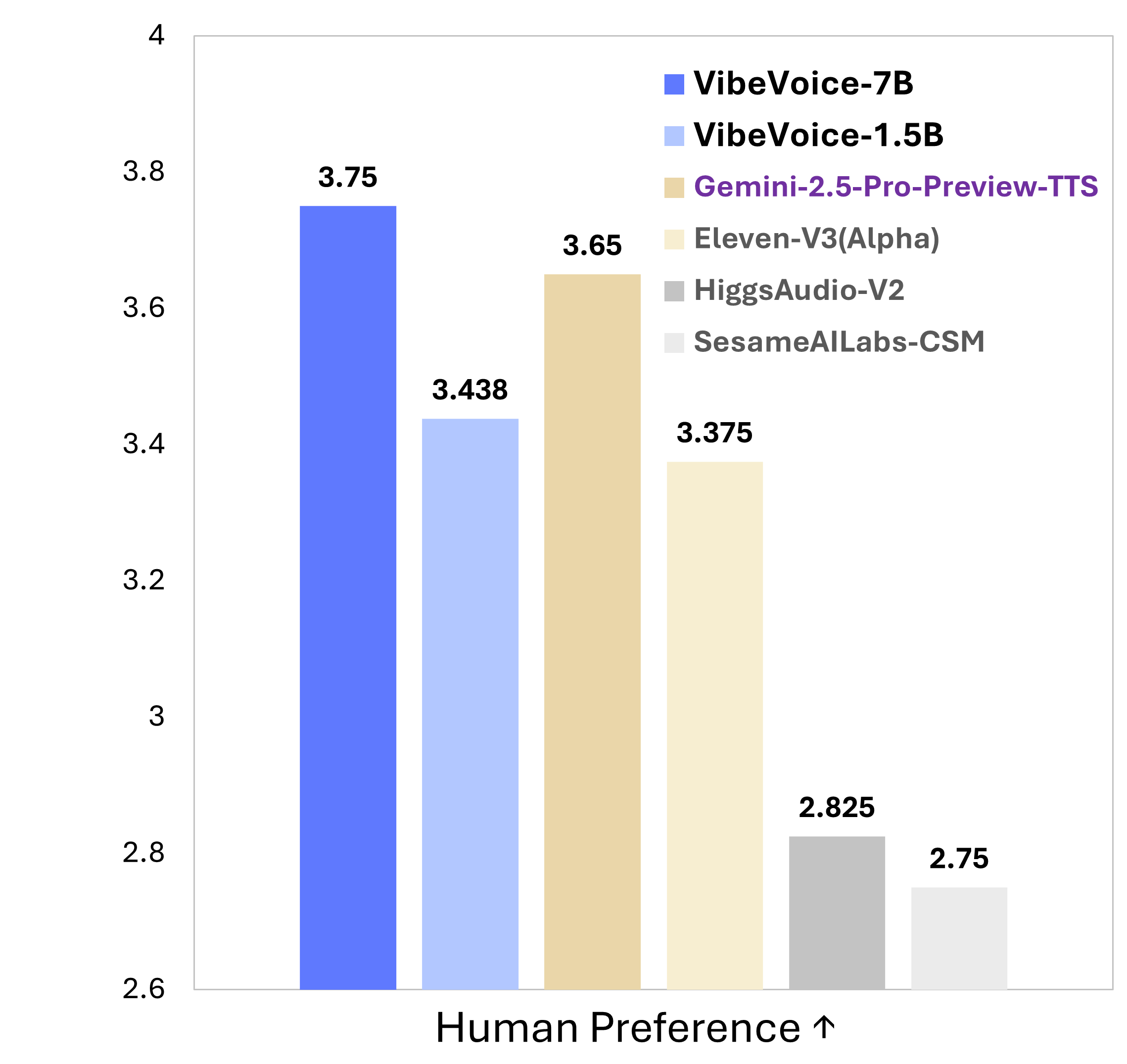
VibeVoiceを選ぶ理由
前例のないスケーラビリティと自然な対話生成を備えた会話型テキスト読み上げ技術の革新的な技術を体験。
VibeVoiceの特別な点
VibeVoiceは、革新的なアーキテクチャと前例のない能力で会話型テキスト読み上げ技術を革命化する画期的なフレームワークです。
連続音声トークナイザー
効率的な長いシーケンス処理のため7.5 Hzの超低周波数で動作する音響および意味トークナイザー
次トークン拡散フレームワーク
LLM理解と拡散ヘッドを組み合わせて高品質な音響詳細を生成
長い多話者サポート
最大4人の異なる話者で最大90分までの自然な会話音声を生成
表現力豊かな会話音声
自然な話者交代を備えたポッドキャスト、インタビュー、多話者対話のために特別に設計
スケーラブルアーキテクチャ
スケーラビリティ、話者一貫性、自然な会話フローの面で従来のTTSの課題を解決
研究フレームワーク
音声合成コミュニティの協力促進を目的としたオープンソース研究フレームワーク
人々が言っていること
コミュニティがVibeVoiceについてどう思っているかを見てください。
Been playing with Microsoft’s VibeVoice, MIT-licensed TTS that does ~90-minute narrations, multi-speaker, cross-lingual.
— Sai (@SAIT112024) August 30, 2025
Streaming and a larger checkpoint are coming. Let’s just say it drops neatly into a local-first stack I care about. pic.twitter.com/TCxDcmAgDj
VibeVoice might be the best FREE text to speech & voice cloner right now.
— ⚡AI Search⚡ (@aisearchio) September 3, 2025
- Over 90min generations
- Up to 4 speakers
- Auto expressions
- Can run on consumer GPUs
See my full tutorial: https://t.co/UnbBzSMZA9 pic.twitter.com/yFDaqEbd5U
VibeVoice 复活啦!
— karminski-牙医 (@karminski3) September 15, 2025
我是没想到 VibeVoice 都快变成 电视剧了,最近社区爱好者们自发的从VibeVoice 历史提交中成功找回了未经河蟹的版本,然后放到了 HuggingFace。由于微软当初是 MIT协议发布的,所以微软也没办法下架这个恢复出来的模型了。
总之,如果你想用 VibeVoice… pic.twitter.com/VxMAklY8kL
微软新开源了这个 VibeVoice TTS模型很强
— 歸藏(guizang.ai) (@op7418) August 26, 2025
- 支持最多生成 90 分钟时长
- 最多4 个人的对谈语音,以往模型只能生成两个
- 支持中文,而且中文效果不错
- 支持生成带背景音乐的播客音频 pic.twitter.com/gnHDl3Apmj
💬 Microsoft > VibeVoice 모델 공개
— lucas (@lucas_flatwhite) September 2, 2025
마이크로소프트에서 공개한 VibeVoice는 텍스트를 입력받아 자연스러운 대화 형식의 오디오를 생성하는 오픈소스 TTS(Text-to-Speech) 모델이에요.
VibeVoice: A Frontier Open-Source Text-to-Speech Modelhttps://t.co/iveNf3unot
Hugging Face… pic.twitter.com/BSlyQItasF
【速報🔥】超高性能TTS「VibeVoice」がコミュニティ主導で劇的復活🎉 長時間&複数人会話音声生成がクリエイターの強力な武器に!
— ハカセ アイ(Ai-Hakase)🐾最新トレンドAIのためのX 🐾 (@ai_hakase_) September 15, 2025
Microsoftが中止した超高性能TTS「VibeVoice」が、コミュニティの情熱で「VibeVoice-Community」として劇的復活しましたよ!🎉… pic.twitter.com/n2k5ROEzQv
VibeVoiceに関するよくある質問
他に質問がありますか?メールでお問い合わせください。
VibeVoiceは何のために設計されていますか?
VibeVoiceは、ポッドキャスト、インタビュー、拡張対話などの表現力豊かな長い多話者会話音声をテキスト入力から生成するために設計されています。
VibeVoiceはどのくらい長い音声を生成できますか?
VibeVoiceは最大90分まで音声を合成でき、通常ははるかに短いシーケンスを処理する従来のTTSシステムを大幅に上回ります。
VibeVoiceは何人の話者を処理できますか?
VibeVoiceは単一会話で最大4人の異なる話者をサポートし、音声全体を通して自然な話者交代と話者一貫性を維持します。
VibeVoiceはどの言語をサポートしていますか?
VibeVoiceは現在英語と中国語をサポートしています。他の言語のテキストは予期しない音声出力を引き起こす可能性があります。
VibeVoiceは商用利用に適していますか?
VibeVoiceは研究開発目的のみに使用されます。追加のテストと開発なしに商用または実際のアプリケーションで使用することは推奨しません。
VibeVoiceを試す準備はできていますか?
会話型テキスト読み上げ技術のパワーを体験してください。