VibeVoice Synthèse Vocale
Un framework innovant pour générer des audios conversationnels expressifs, longs et multi-locuteurs à partir de texte. Utilise des tokeniseurs à ultra-basse fréquence et la diffusion next-token pour une synthèse vocale de haute qualité jusqu'à 90 minutes avec 4 locuteurs distincts.
Fonctionnalités Clés
- •Audio conversationnel long (jusqu'à 90 minutes)
- •Support multi-locuteurs (jusqu'à 4 locuteurs distincts)
- •Tokeniseurs à ultra-basse fréquence (7.5 Hz)
- •Framework de diffusion next-token
🎁 Découvrez l'avenir de la technologie de synthèse vocale conversationnelle
Qu'est-ce que VibeVoice
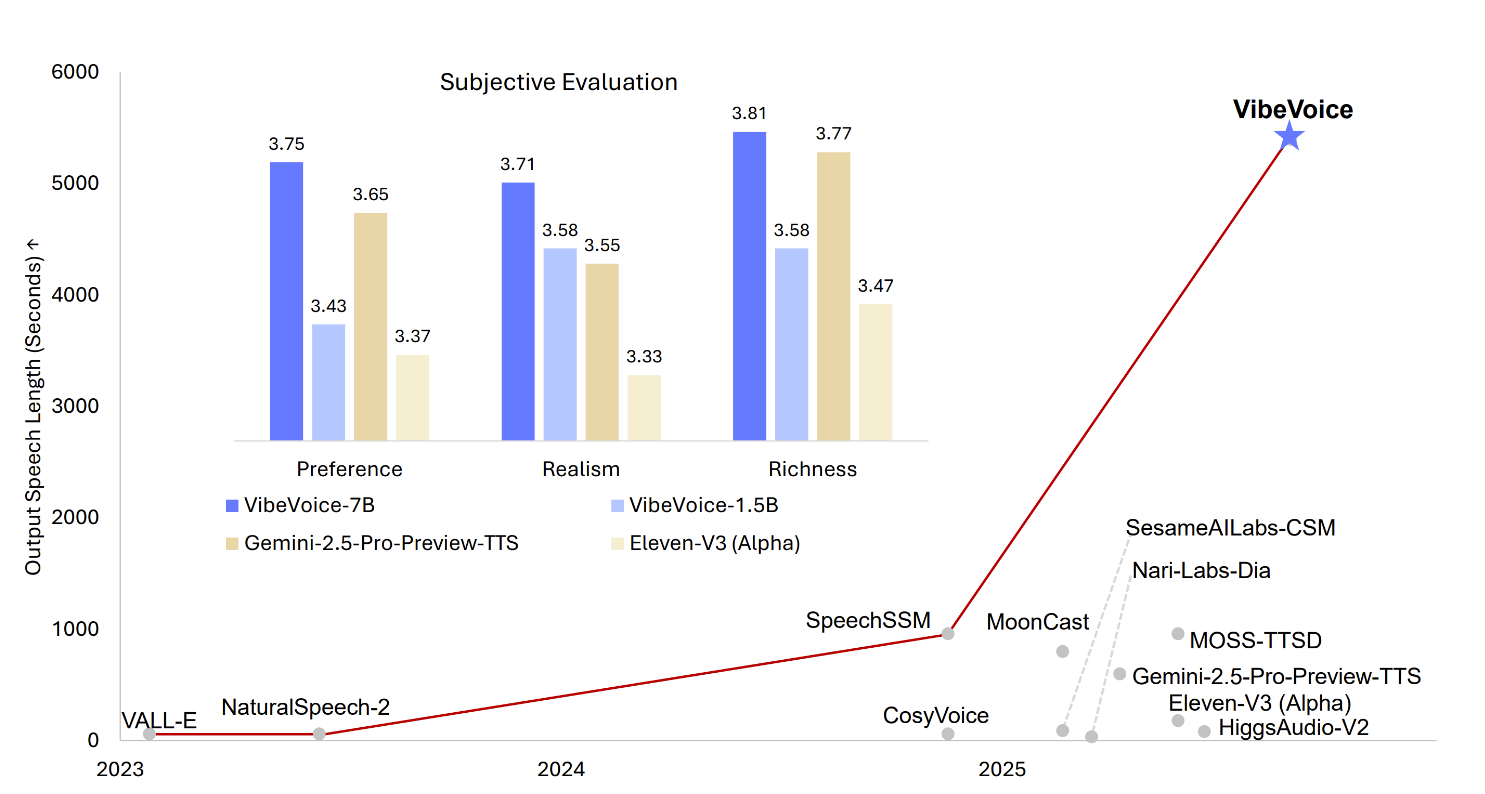
VibeVoice est un framework innovant conçu pour générer des audios conversationnels expressifs, longs et multi-locuteurs à partir de texte. Il résout des défis significatifs des systèmes TTS traditionnels, particulièrement en scalabilité, cohérence des locuteurs et transition naturelle entre les locuteurs.
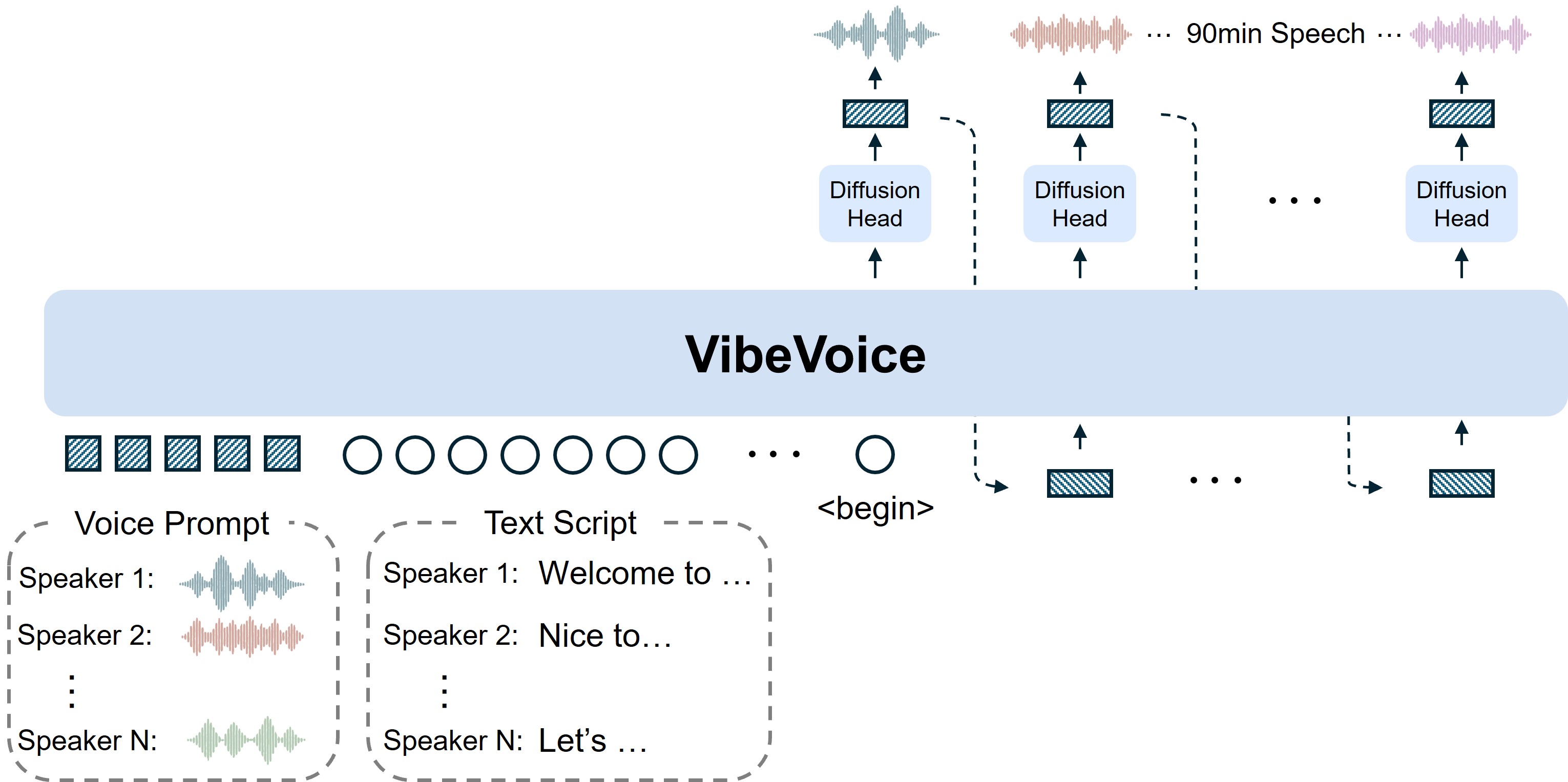
- Tokeniseurs vocaux continusUtilise des tokeniseurs acoustiques et sémantiques fonctionnant à une fréquence ultra-basse de 7.5 Hz, préservant efficacement la fidélité audio tout en augmentant considérablement l'efficacité computationnelle.
- Framework de diffusion next-tokenExploite un grand modèle de langage pour comprendre le contexte textuel et le flux conversationnel, avec une tête de diffusion pour générer des détails acoustiques haute fidélité.
- Support multi-locuteurs longSyntétise la parole jusqu'à 90 minutes avec jusqu'à 4 locuteurs distincts, surpassant les limites typiques de 1-2 locuteurs des modèles précédents.
Pourquoi choisir VibeVoice
Découvrez une technologie révolutionnaire en synthèse vocale conversationnelle avec une scalabilité sans précédent et une génération de dialogue naturelle.
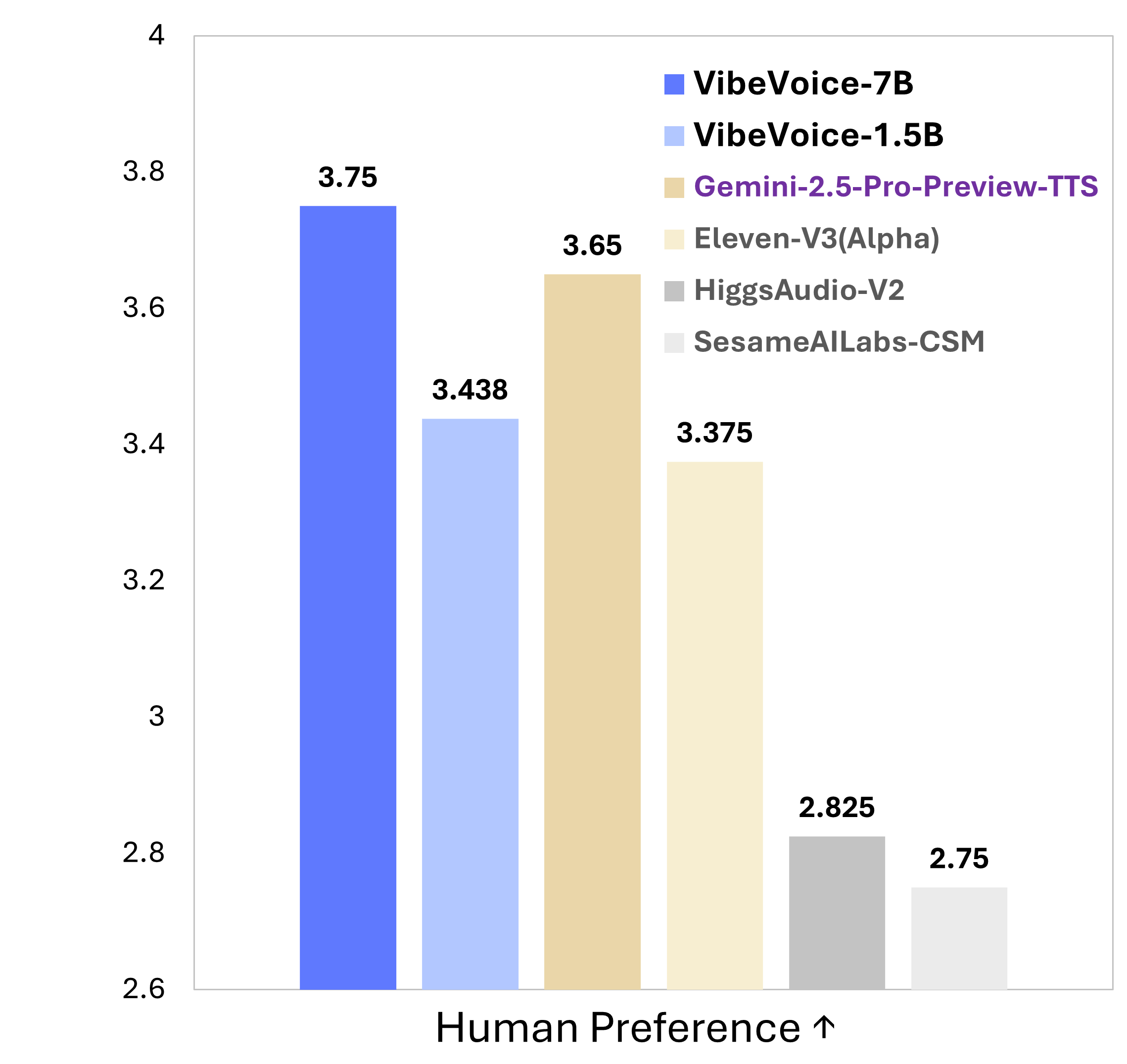
Ce qui rend VibeVoice spécial
VibeVoice est un framework révolutionnaire qui transforme la synthèse vocale conversationnelle avec son architecture innovante et ses capacités sans précédent.
Tokeniseurs vocaux continus
Tokeniseurs acoustiques et sémantiques fonctionnant à une fréquence ultra-basse de 7.5 Hz pour un traitement efficace des longues séquences
Framework de diffusion next-token
Combine la compréhension LLM avec une tête de diffusion pour générer des détails acoustiques haute fidélité
Support multi-locuteurs long
Génère jusqu'à 90 minutes d'audio avec jusqu'à 4 locuteurs distincts dans des conversations naturelles
Audio conversationnel expressif
Conçu spécifiquement pour les podcasts, interviews et dialogues multi-locuteurs avec transition naturelle entre les locuteurs
Architecture scalable
Résout les défis traditionnels TTS en scalabilité, cohérence des locuteurs et flux conversationnel naturel
Framework de recherche
Framework de recherche open-source destiné à faire progresser la collaboration dans la communauté de synthèse vocale
Ce que disent les gens
Découvrez ce que la communauté pense de VibeVoice.
Been playing with Microsoft’s VibeVoice, MIT-licensed TTS that does ~90-minute narrations, multi-speaker, cross-lingual.
— Sai (@SAIT112024) August 30, 2025
Streaming and a larger checkpoint are coming. Let’s just say it drops neatly into a local-first stack I care about. pic.twitter.com/TCxDcmAgDj
VibeVoice might be the best FREE text to speech & voice cloner right now.
— ⚡AI Search⚡ (@aisearchio) September 3, 2025
- Over 90min generations
- Up to 4 speakers
- Auto expressions
- Can run on consumer GPUs
See my full tutorial: https://t.co/UnbBzSMZA9 pic.twitter.com/yFDaqEbd5U
VibeVoice 复活啦!
— karminski-牙医 (@karminski3) September 15, 2025
我是没想到 VibeVoice 都快变成 电视剧了,最近社区爱好者们自发的从VibeVoice 历史提交中成功找回了未经河蟹的版本,然后放到了 HuggingFace。由于微软当初是 MIT协议发布的,所以微软也没办法下架这个恢复出来的模型了。
总之,如果你想用 VibeVoice… pic.twitter.com/VxMAklY8kL
微软新开源了这个 VibeVoice TTS模型很强
— 歸藏(guizang.ai) (@op7418) August 26, 2025
- 支持最多生成 90 分钟时长
- 最多4 个人的对谈语音,以往模型只能生成两个
- 支持中文,而且中文效果不错
- 支持生成带背景音乐的播客音频 pic.twitter.com/gnHDl3Apmj
💬 Microsoft > VibeVoice 모델 공개
— lucas (@lucas_flatwhite) September 2, 2025
마이크로소프트에서 공개한 VibeVoice는 텍스트를 입력받아 자연스러운 대화 형식의 오디오를 생성하는 오픈소스 TTS(Text-to-Speech) 모델이에요.
VibeVoice: A Frontier Open-Source Text-to-Speech Modelhttps://t.co/iveNf3unot
Hugging Face… pic.twitter.com/BSlyQItasF
【速報🔥】超高性能TTS「VibeVoice」がコミュニティ主導で劇的復活🎉 長時間&複数人会話音声生成がクリエイターの強力な武器に!
— ハカセ アイ(Ai-Hakase)🐾最新トレンドAIのためのX 🐾 (@ai_hakase_) September 15, 2025
Microsoftが中止した超高性能TTS「VibeVoice」が、コミュニティの情熱で「VibeVoice-Community」として劇的復活しましたよ!🎉… pic.twitter.com/n2k5ROEzQv
Questions fréquemment posées sur VibeVoice
Vous avez une autre question ? Contactez-nous par email.
À quoi VibeVoice est-il conçu ?
VibeVoice est conçu pour générer des audios conversationnels expressifs, longs et multi-locuteurs comme les podcasts, interviews et dialogues étendus à partir d'entrées textuelles.
Combien de temps VibeVoice peut-il générer de l'audio ?
VibeVoice peut synthétiser la parole jusqu'à 90 minutes, ce qui est considérablement plus long que les systèmes TTS traditionnels qui traitent généralement des séquences beaucoup plus courtes.
Combien de locuteurs VibeVoice peut-il gérer ?
VibeVoice supporte jusqu'à 4 locuteurs distincts dans une seule conversation, avec transition naturelle entre les locuteurs et cohérence des locuteurs tout au long de l'audio.
Quelles langues VibeVoice supporte-t-il ?
VibeVoice supporte actuellement l'anglais et le chinois. Les transcriptions dans d'autres langues peuvent entraîner des sorties audio inattendues.
VibeVoice est-il adapté à un usage commercial ?
VibeVoice est destiné uniquement à des fins de recherche et développement. Nous ne recommandons pas de l'utiliser dans des applications commerciales ou réelles sans tests et développement supplémentaires.
Prêt à essayer VibeVoice ?
Découvrez la puissance de la technologie de synthèse vocale conversationnelle.