VibeVoice Text-zu-Sprache
Ein innovatives Framework zur Generierung ausdrucksvoller, langer, mehrsprachiger Gesprächsaudio aus Text. Verwendet Ultra-Niedrigfrequenz-Tokenizer und Next-Token-Diffusion für hochwertige Sprachsynthese bis zu 90 Minuten mit 4 verschiedenen Sprechern.
Hauptfunktionen
- •Lange Gesprächsaudio (bis zu 90 Minuten)
- •Mehrsprachige Unterstützung (bis zu 4 verschiedene Sprecher)
- •Ultra-Niedrigfrequenz-Tokenizer (7.5 Hz)
- •Next-Token-Diffusion-Framework
🎁 Erleben Sie die Zukunft der Gesprächs-Text-zu-Sprache-Technologie
Was ist VibeVoice
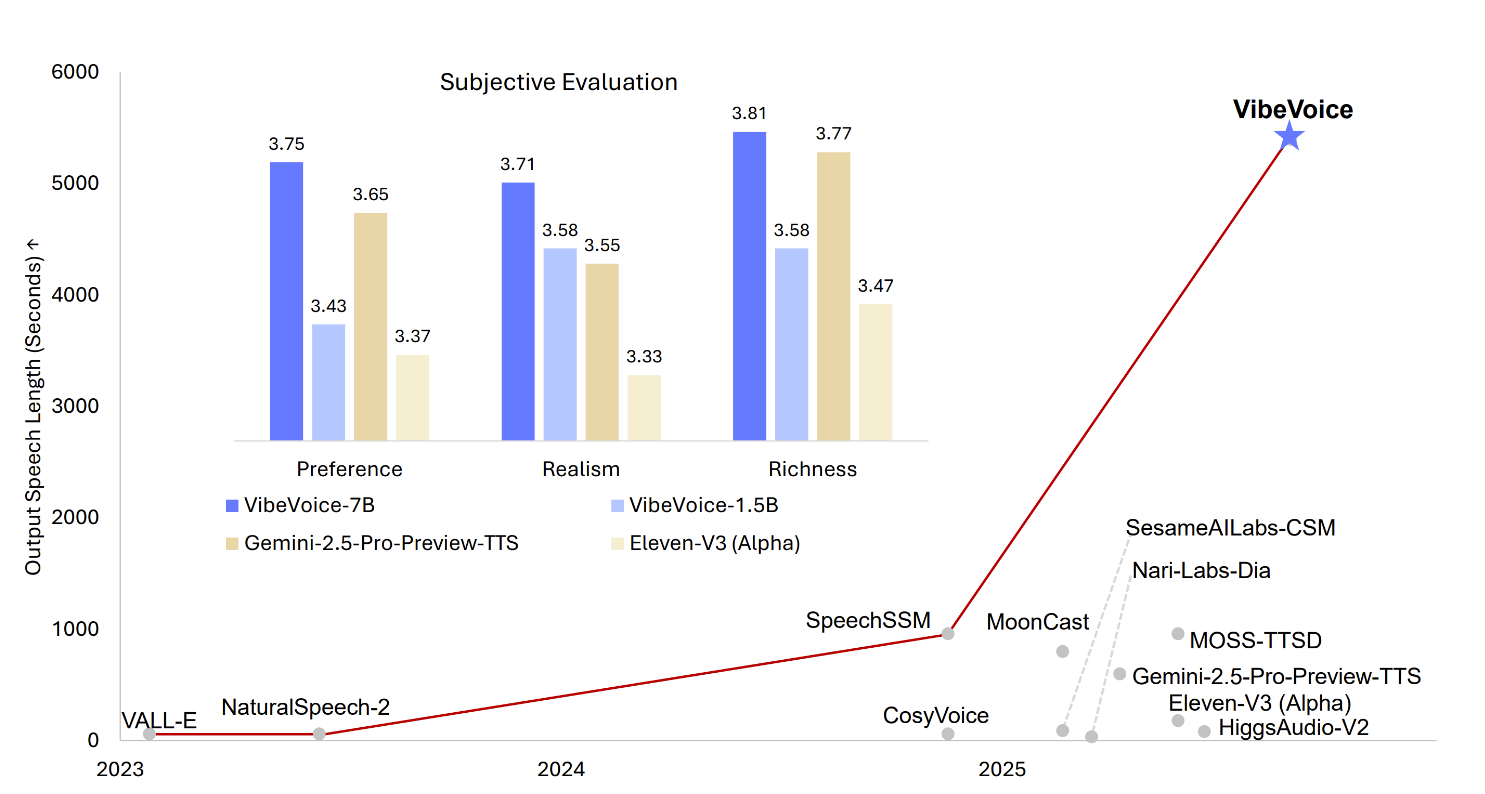
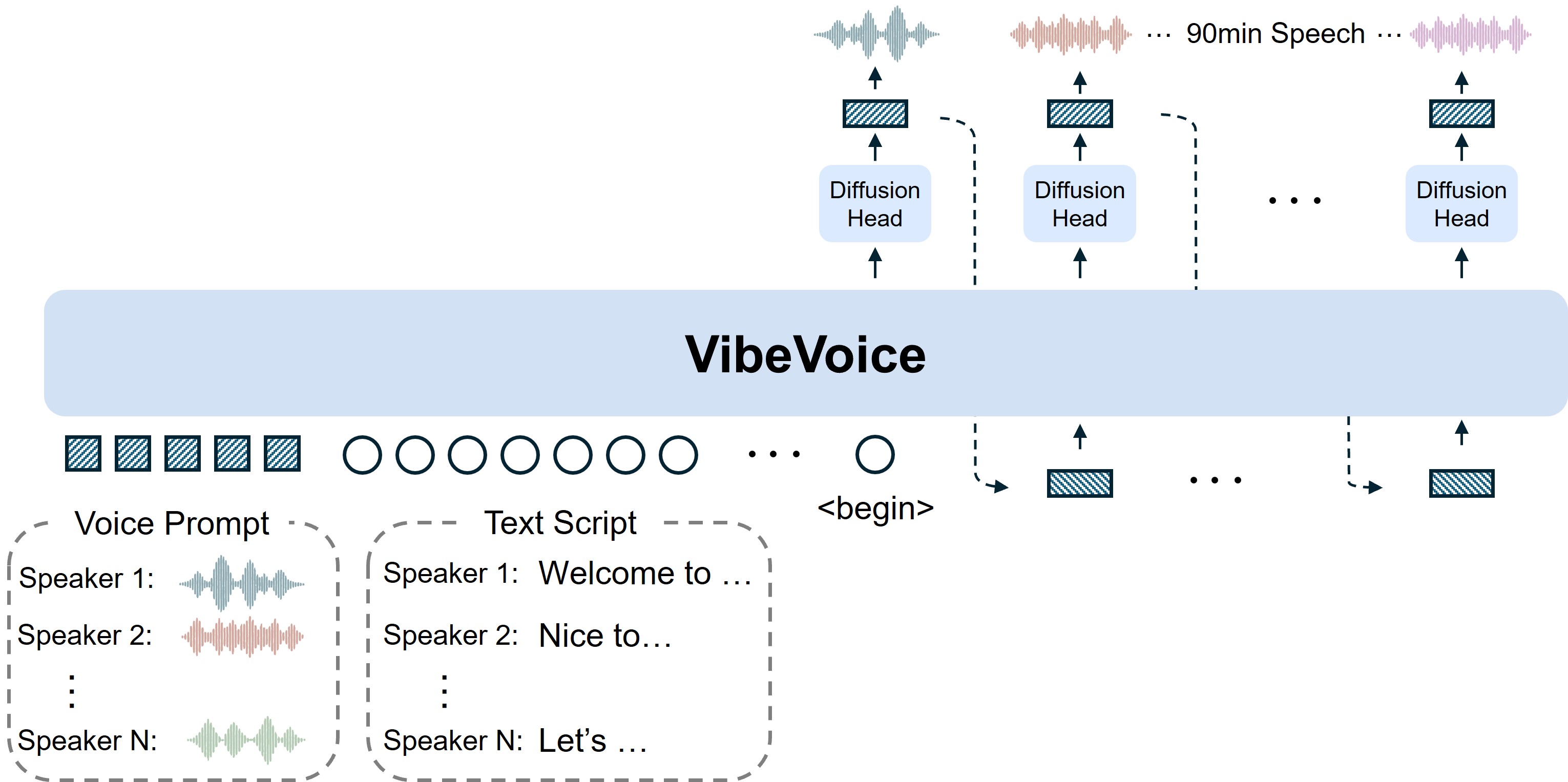
VibeVoice ist ein innovatives Framework zur Generierung ausdrucksvoller, langer, mehrsprachiger Gesprächsaudio aus Text. Es löst bedeutende Herausforderungen traditioneller TTS-Systeme, insbesondere in Skalierbarkeit, Sprecherkonsistenz und natürlichem Sprecherwechsel.
- Kontinuierliche Sprach-TokenizerVerwendet akustische und semantische Tokenizer mit Ultra-Niedrigfrequenz von 7.5 Hz, die effizient die Audio-Treue bewahren und gleichzeitig die Recheneffizienz erheblich steigern.
- Next-Token-Diffusion-FrameworkNutzt ein großes Sprachmodell zum Verständnis von Textkontext und Gesprächsfluss, mit einem Diffusionskopf zur Generierung hochwertiger akustischer Details.
- Lange Mehrsprachige UnterstützungSynthetisiert Sprache bis zu 90 Minuten mit bis zu 4 verschiedenen Sprechern und übertrifft die typischen 1-2 Sprecher-Limits früherer Modelle.
Warum VibeVoice wählen
Erleben Sie bahnbrechende Technologie in der Gesprächs-Text-zu-Sprache mit beispielloser Skalierbarkeit und natürlicher Dialoggenerierung.
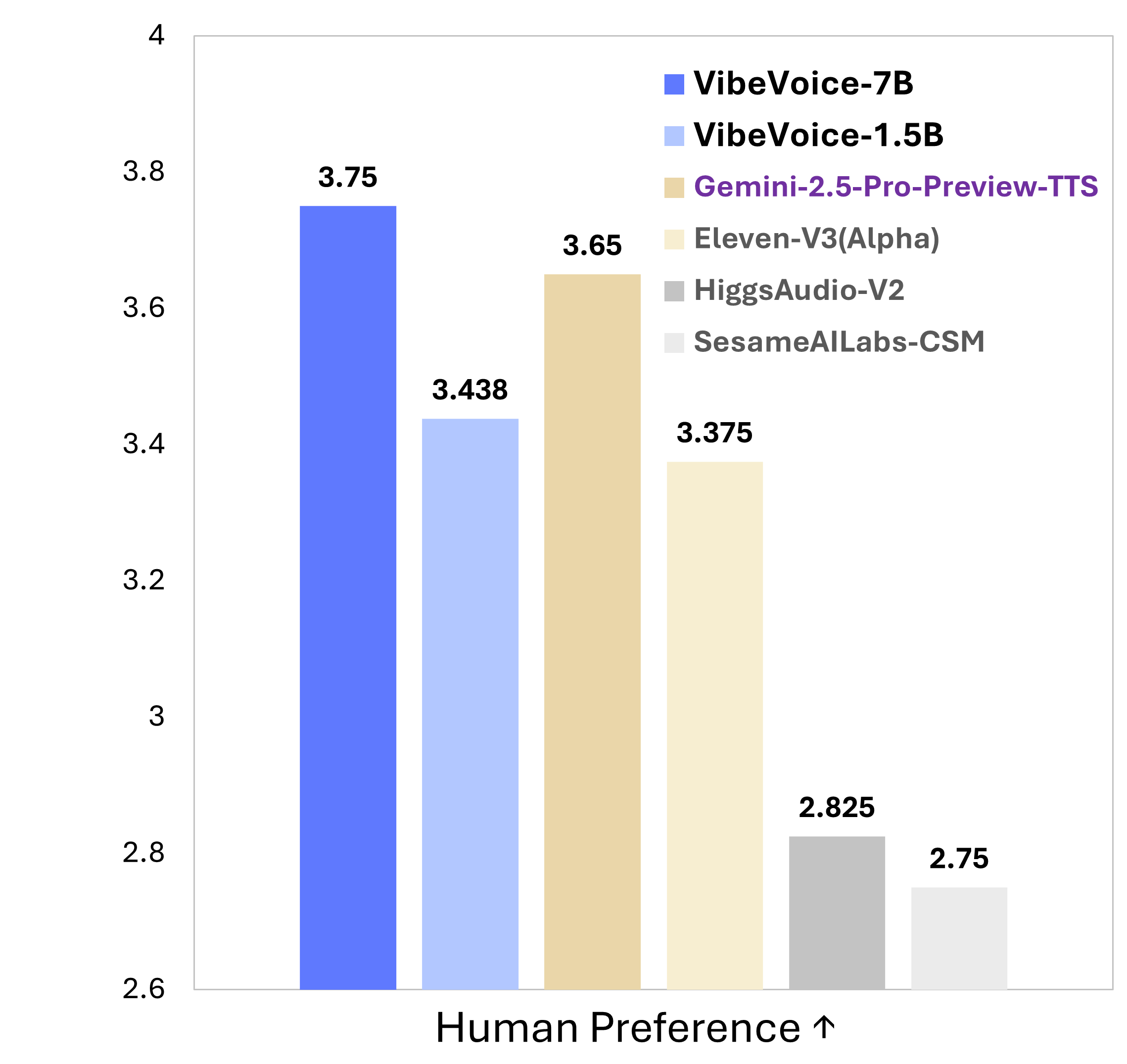
Was macht VibeVoice besonders
VibeVoice ist ein bahnbrechendes Framework, das die Gesprächs-Text-zu-Sprache mit seiner innovativen Architektur und beispiellosen Fähigkeiten revolutioniert.
Kontinuierliche Sprach-Tokenizer
Akustische und semantische Tokenizer mit Ultra-Niedrigfrequenz von 7.5 Hz für effiziente Verarbeitung langer Sequenzen
Next-Token-Diffusion-Framework
Kombiniert LLM-Verständnis mit Diffusionskopf für hochwertige akustische Detailgenerierung
Lange Mehrsprachige Unterstützung
Generieren Sie bis zu 90 Minuten Audio mit bis zu 4 verschiedenen Sprechern in natürlichen Gesprächen
Ausdrucksvolles Gesprächsaudio
Speziell für Podcasts, Interviews und mehrsprachige Dialoge mit natürlichem Sprecherwechsel entwickelt
Skalierbare Architektur
Löst traditionelle TTS-Herausforderungen in Skalierbarkeit, Sprecherkonsistenz und natürlichem Gesprächsfluss
Forschungsframework
Open-Source-Forschungsframework zur Förderung der Zusammenarbeit in der Sprachsynthese-Community
Was Menschen sagen
Sehen Sie, was die Community über VibeVoice denkt.
Been playing with Microsoft’s VibeVoice, MIT-licensed TTS that does ~90-minute narrations, multi-speaker, cross-lingual.
— Sai (@SAIT112024) August 30, 2025
Streaming and a larger checkpoint are coming. Let’s just say it drops neatly into a local-first stack I care about. pic.twitter.com/TCxDcmAgDj
VibeVoice might be the best FREE text to speech & voice cloner right now.
— ⚡AI Search⚡ (@aisearchio) September 3, 2025
- Over 90min generations
- Up to 4 speakers
- Auto expressions
- Can run on consumer GPUs
See my full tutorial: https://t.co/UnbBzSMZA9 pic.twitter.com/yFDaqEbd5U
VibeVoice 复活啦!
— karminski-牙医 (@karminski3) September 15, 2025
我是没想到 VibeVoice 都快变成 电视剧了,最近社区爱好者们自发的从VibeVoice 历史提交中成功找回了未经河蟹的版本,然后放到了 HuggingFace。由于微软当初是 MIT协议发布的,所以微软也没办法下架这个恢复出来的模型了。
总之,如果你想用 VibeVoice… pic.twitter.com/VxMAklY8kL
微软新开源了这个 VibeVoice TTS模型很强
— 歸藏(guizang.ai) (@op7418) August 26, 2025
- 支持最多生成 90 分钟时长
- 最多4 个人的对谈语音,以往模型只能生成两个
- 支持中文,而且中文效果不错
- 支持生成带背景音乐的播客音频 pic.twitter.com/gnHDl3Apmj
💬 Microsoft > VibeVoice 모델 공개
— lucas (@lucas_flatwhite) September 2, 2025
마이크로소프트에서 공개한 VibeVoice는 텍스트를 입력받아 자연스러운 대화 형식의 오디오를 생성하는 오픈소스 TTS(Text-to-Speech) 모델이에요.
VibeVoice: A Frontier Open-Source Text-to-Speech Modelhttps://t.co/iveNf3unot
Hugging Face… pic.twitter.com/BSlyQItasF
【速報🔥】超高性能TTS「VibeVoice」がコミュニティ主導で劇的復活🎉 長時間&複数人会話音声生成がクリエイターの強力な武器に!
— ハカセ アイ(Ai-Hakase)🐾最新トレンドAIのためのX 🐾 (@ai_hakase_) September 15, 2025
Microsoftが中止した超高性能TTS「VibeVoice」が、コミュニティの情熱で「VibeVoice-Community」として劇的復活しましたよ!🎉… pic.twitter.com/n2k5ROEzQv
Häufig gestellte Fragen zu VibeVoice
Haben Sie eine andere Frage? Kontaktieren Sie uns per E-Mail.
Wofür ist VibeVoice konzipiert?
VibeVoice ist für die Generierung ausdrucksvoller, langer, mehrsprachiger Gesprächsaudio wie Podcasts, Interviews und erweiterte Dialoge aus Texteingabe konzipiert.
Wie lange kann VibeVoice Audio generieren?
VibeVoice kann Sprache bis zu 90 Minuten synthetisieren, was deutlich länger ist als traditionelle TTS-Systeme, die normalerweise viel kürzere Sequenzen verarbeiten.
Wie viele Sprecher kann VibeVoice verarbeiten?
VibeVoice unterstützt bis zu 4 verschiedene Sprecher in einem einzigen Gespräch mit natürlichem Sprecherwechsel und Sprecherkonsistenz während des gesamten Audios.
Welche Sprachen unterstützt VibeVoice?
VibeVoice unterstützt derzeit Englisch und Chinesisch. Texte in anderen Sprachen können zu unerwarteten Audio-Ausgaben führen.
Ist VibeVoice für kommerzielle Nutzung geeignet?
VibeVoice ist nur für Forschungs- und Entwicklungszwecke bestimmt. Wir empfehlen nicht, es ohne weitere Tests und Entwicklung in kommerziellen oder realen Anwendungen zu verwenden.
Bereit, VibeVoice zu testen?
Erleben Sie die Kraft der Gesprächs-Text-zu-Sprache-Technologie.